
近年来,BERT、GPT-2等深度学习语言模型,极大地提高了问答、摘要、人机对话等下游自然语言处理任务的性能。
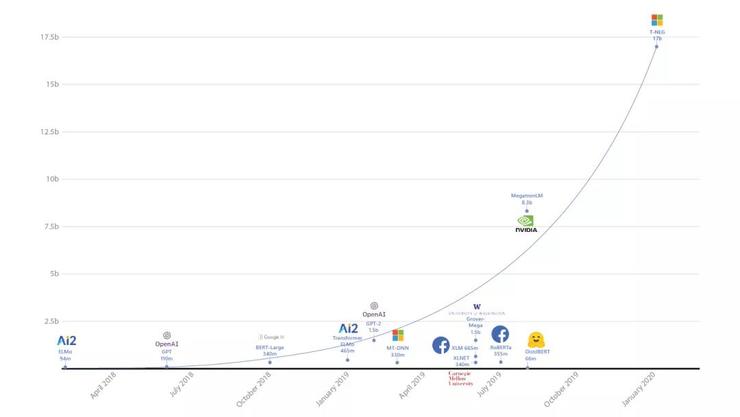
而今天,微软研究院重磅发布了有史以来最大的基于Transformer架构的语言生成模型 Turing-NLG。此模型的参数高达170亿,是英伟达的Megatron(也就是现在第二大Transformer模型)的两倍,是OpenAI的GPT-2的十倍。
基于Transformer的架构,意味着该模型可以生成词来完成开放式文本任务。除了填充不完整语句外,它还可以对输入文档的问题和摘要生成答案。
而微软之所以能够开发出 Turing-NLG 这一重磅级的语言生成模型,实际上离不开其差不多同一时间开源的深度学习库——DeepSpeed。
微软表示,DeepSpeed 能够让他们降低模型并行度(从16降低到4),将每个节点的批处理大小增加4倍,并将训练时间减少到原来的1/3。不仅如此,DeepSpeed 使用更少的GPU 就可以提高大型模型的训练效率。
一、Turing-NLG:自带170亿参数,性能超其他最佳模型
Turing-NLG 一个基于Transformer的生成语言模型,拥有 170亿参数,在诸多语言模型基准上都超越了当前性能最佳的其他模型,并且在应用于问答、摘要等实践任务时,表现出色。此前的问答和摘要系统依赖于从文档中提取现有的内容作为生成答案和摘要的“立足点”,这样生成的结果往往是不自然且不连贯的。而Turing-NLG 则能够非常自然地完成问答和摘要任务。
1、开发Turing-NLG 所依赖的硬件和软件突破
实际上,参数超过 13亿的任何模型都无法装入单个的GPU(即便是内存为 32 GB),因而模型本身需要在多个 GPU 上实现并行化。
据微软介绍,训练 Turing-NLG 模型主要基于硬件和软件实现的以下几个突破:
第一,他们使用了NVIDIA 新一代超级计算机 DGX-2的硬件配置,结合InfiniBand连接技术,从而让GPU 之间的通信比此前更迅速得多。
第二,他们在 NVIDIA的 Megatron-LM 框架上应用 Tensor切片对横跨 4 个 NVIDIA V100 GPU 的模型进行切片处理;
第三,ZeRO 优化器和DeepSpeed库,则让他们降低了模型的并行度(从16降到4 ),将每个节点的批处理大小增加了4倍,并将训练时间减少到原来的1/3。
并且,DeepSpeed 使用更少的GPU 就可以提高大型模型的训练效率,它在训练大小为 512 的批处理时仅需要256个NVIDIA的 GPU,而仅使用Megatron-LM 框架的模型则需要1024个NVIDIA的 GPU。
相同条件设置下,Turing-NLG 模型和Open AI 的GPT-2 、Megatron-LM 模型在标准语言任务上的性能指标——WikiText-103 困惑度(越低性能越好)、LAMBADA 下一个词的预测准确度(越高性能越好)的对比情况如下表:
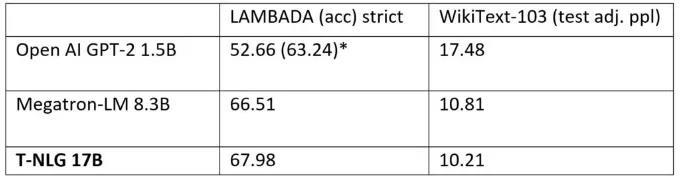
Open AI 使用了额外的处理(停用词过滤)让 GPT-2 实现了更好的表现,而Turing-NLG 和Megatron-LM 模型都没有使用到该停用词过滤技术。无论在WikiText-103 困惑度上还是在LAMBADA 下一个词的预测准确度上,Turing-NLG 模型的表现都优于Open AI GPT-2和Megatron-LM 模型。而下图则展示了Turing-NLG模型(蓝线和绿线)和Megatron-LM 模型(橙线)在验证困惑度上的表现对比情况:
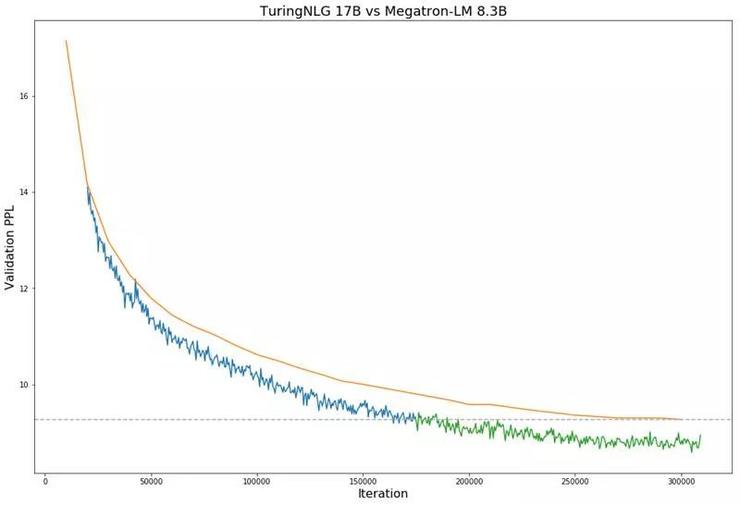
(雷锋网出品)图1:Turing-NLG 17B 模型(蓝线和绿线)和Megatron-8B 模型(橙线)在验证困惑度上的对比图。虚线表示当前性能最佳模型实现的最低验证损失。图中从蓝线到绿色的转换,代表 Turing-NLG 模型的性能从弱于当前性能最佳模型到超越当前性能最佳模型的转变。据图显示,Turing-NLG 模型在验证困惑度上的表现也始终要比Megatron-LM 模型要好。
2、Turing-NLG 在问答和摘要任务上实现的两大突破
在问答和摘要任务上,Turing-NLG 分别实现了两个方面的突破:
1)实现了直接生成问答或在零样本下生成问答的能力很多网络用户在网页上搜索问题的时候,往往会在答案页面的顶部看到一张答案卡片,而这些答案大多为某个段落上下文中可以回答问题的句子。
Turing-NLG 则可以直接回答用户的问题,从而满足他们的信息搜索需求。例如,当用户搜索“Jason Mraz 与谁订婚了?”时,大多数搜索引擎在展示完整的答案页面时,会突出显示“Tristan Prettyman”这个名字,如下图所示:

而Turing-NLG则会直接用一个完整的句子:“Jason Mraz 与Tristan Prettyman订婚了”。
在网页搜索以外的应用场景中,这种直接生成回答的能力还要更加重要,例如,当用户询问其个人输入(如电子邮箱或Word 文档)时,这种能力能够让 AI 助手智能化地对此问题进行回复,更加自然而不显得突兀。Turing-NLG 模型还拥有“零样本”问答的能力,也就是说能够在没有上下文段落的情况下,回答问题。下图展示了该模型在没有给出段落的情况下直接回答问题的两个案例:

(雷锋网出品)
在该情况下,Turing-NLG 模型依赖预训练期间所获得的知识,生成了最终的答案。下图展示了Turing-NLG 模型和此前的基准系统(类似于CopyNet的 LSTM模型)在事实正确性(Factual Correctness)和语法正确性(Grammatical Correctness)两项指标上的对比情况:

微软研究者发现,大型的预训练模型需要更少下游任务的示例来更好地对其进行学习,而他们仅仅只有最多100,000 个“直接”回答问题的样本,并且模型训练的示例也非常少,在这样的情况下,Turing-NLG 模型无论在事实正确性(Factual Correctness)和语法正确性(Grammatical Correctness)上,都比 LSTM 基准模型的表现更好。
2)能够在更少的监督下生成抽象式摘要在自然语言处理的文献中,摘要分为两种:提取式摘要:从文档中提取出少量的句子作为摘要内容;抽象式摘要:使用 NLG 模型生成摘要,就像人类做摘要的方式一样。而Turing-NLG模型则旨在像人类一样,为电子邮件、博客文章、Word 文档甚至是Excel 表格和PPT 演示等各种各样的文本文档“编写”抽象式摘要。
其中一个主要的挑战便是缺少面向这些场景的有监督的训练数据,因为人类并不总会明确地对这些文档类型做摘要处理。而 Turing-NLG 的强大之处则在于,它非常擅长理解文本,以至于不需要太多的监督就能够比其他摘要技术,表现更好。
为了让Turing-NLG 尽可能广泛地为不同类型的文本生成摘要,研究者们还在几乎所有对外开放的摘要数据集上,采用多任务模式对Turing-NLG模型进行了微调。下图展示了 Turing-NLG 模型和 PEGASUS(同样为最近新提出的基于Transformer的语言模型)、SOTA(先前性能最佳的语言模型)在 ROUGE评价指标上的对比情况:
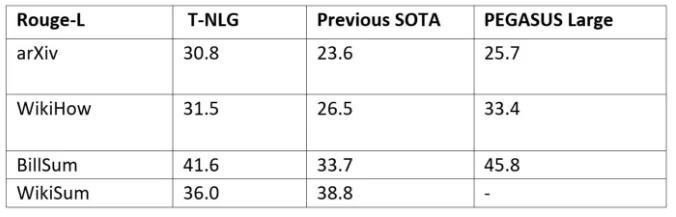
其中需要注意的是,Turing-NLG 采用多任务模式进行了训练,即在所有数据集上进行了同步训练。而众所周知,ROUGE评价指标在摘要任务方面存在一定的缺陷,因而在下表中展示了Turing-NLG 模型对一些公开文章输出的摘要内容以供参考:
二、ZeRO & DeepSpeed:优化器+深度学习库助力大模型训练
正如上所述,Turing-NLG是建立在ZeRO 优化器和DeepSpeed库基础上开发出来的。DeepSpeed作为微软最新发布的深度学习开源库,能够提高模型训练的速度、成本以及可用性。更为重要的是,最新发布的DeepSpeed解锁了其训练1000亿参数模型的能力,虽然不是超参数的数量,但是在大规模数据训练领域也算是首屈一指了。
DeepSpeed与PyTorch兼容,里面内嵌ZeRO并行优化器,利用这个优化器,可以大大减少模型和数据并行性所需的资源,同时可以大幅度增加可训练的参数数量。具体而言,零冗余优化器(Zero Redundancy Optimizer,简称Zero)是一种面向大规模分布式深度学习的新型存储优化技术。其可以在当前一代GPU集群上训练1000亿个参数的深度学习模型,吞吐量大概是当前最棒系统的3到5倍。
1、使用ZeRO克服数据并行性和模型并行性的局限性

毋庸置疑,大型的深度学习模型可以显著提高准确度,但是直接训练数带有十亿参数的模型,硬件往往受不了。为了解决这种硬件内存问题,通常的解决方案是兼顾计算资源、效率,但是往往却有以下两点限制:
数据的并行性对节约设备的内存起不到什么作用:即使32G的GUP,在面对10亿个参数的模型也束手无策。
由于细粒度并行计算和通信昂贵,模型并行不能有效地扩展到单个节点之外。
但是,使用ZeRO可以克服数据并行性和模型并行性的局限。ZeRO通过跨数据并行进程划分模型状态(参数,梯度和优化器状态),在一定程度上能够消除数据并行进程之间的内存冗余。ZeRO还能够在模型训练期间动态规划通信,保证了分布式设备之间共享必要的状态,从而保持数据粒度的计算和通信量。换句话说ZeRO允许每个设备的内存使用量随数据并行性的程度而进行线性扩展,也即只要聚合的设备内存足够大,ZeRO支持的数据并行性可以“拿下”任意大小的模型。
ZeRO主要有三个优化阶段,如下图所示分,这三个阶段别是:优化器状态、梯度和参数的划分。
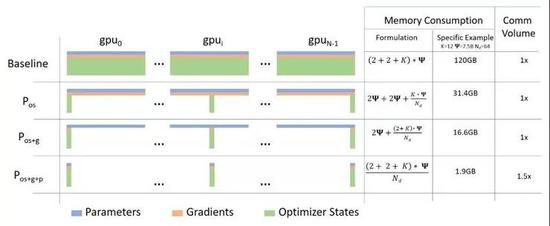
图注:与标准数据并行基准相比,ZeRO的三个阶段节省的内存和通信量。其中Ψ表示模型中参数的数量,K是优化器特定的常数项。
更为具体的:优化器状态分区(Pos)阶段内存降低到了原来的1/4;增加梯度分区((Pos+g)阶段内存减少到原来的1/8,此外。通信量与数据并行度相同;添加参数分区阶段内存减少量与数据并行度Nd成线性关系。启用上述所有个阶段后,使用ZeRO就可以用1024个 NVIDIA 型号的GPU 上训练一个万亿参数模型。
如果使用具16位精度的Adam来训练一个万亿参数级别的模型大概需要16TB的内存才能让优化器保持训练状态。16TB除以1024等于16GB,还好在GPU内存的合理范围。
2、DeepSpeed:PyTorch兼容性和系统性能
前面也提到,最先发布DeepSpeed能够与PyTorch兼容,并且引入的轻量级API 包含最新的训练技术,例如ZeRO,分布式训练,混合精度等等。在操作层面上,只需对PyTorch模型进行简单的几行代码更改,就可以利用DeepSpeed提高模型训练的速度和规模。
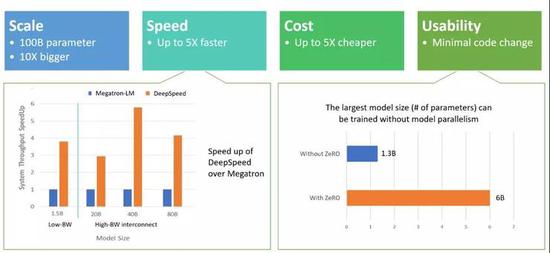
左图:与Megatron-LM相比吞吐量的程度。右图:使用和不使用ZeRO时,对于单独使用数据并行性的可训练模型大小比较。
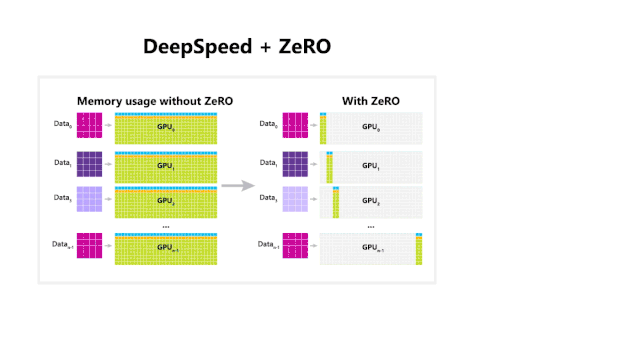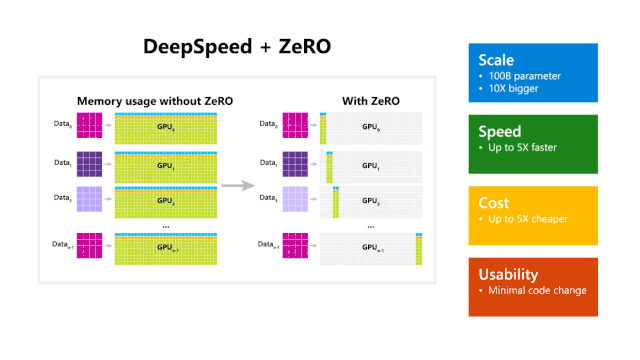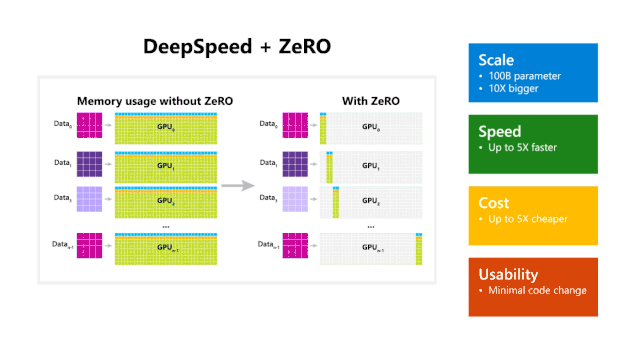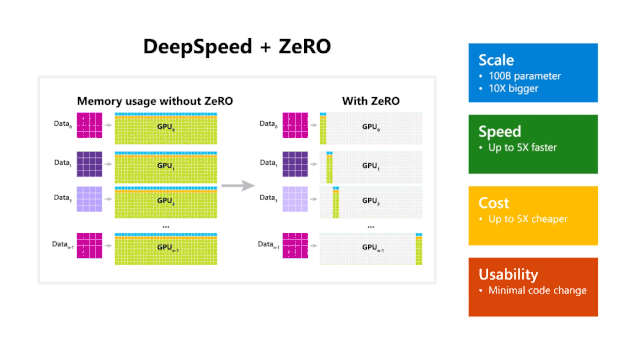
如上图所示,DeepSpeed在规模、速度、成本、可用性这四个方面标新都非常出色。
规模:当前最先进的大规模训练,例如OpenAI GPT-2,NVIDIA Megatron-LM和Google T5,其大小也就分别是15亿、83亿和110亿个参数。而有ZeRO加持的DeepSpeed能够运行1000亿个参数。
速度:现有的吞吐量比当前最先进的技术都要高出5倍。例如为了能够在GPT系列有效训练模型,DeepSpeed将ZeRO功率(ZeRO-powered)数据并行与NVIDIA Megatron-LM模型并行相结合。另外,在具有低带宽互连的NVIDIA GPU群集上,对具有15亿参数的标准GPT-2模型,与单独使用Megatron-LM相比,吞吐量提高了3.75倍。这种速度的提高与DeepSpeed更高的内存效率以及使用较低程度的模型并行有关,当然较大的批处理量也在提高吞吐量的工作中做了贡献。
成本:提高吞吐量的同时,对训练成本的节约也是非常大的。例如,要训练具有200亿个参数的模型,传统则比DeepSpeed需要的资源多3倍。
可用性:只需更改几行代码就可在PyTorch模型中使用DeepSpeed和ZeRO。也就是说与当前的模型并行性库相比,DeepSpeed不需要重新设计代码或重构模型,即使对于参数多达60亿的模型,也可以方便地使用ZeRO提供支持的数据并行性。
综上所述,ZeRO-OS与不同类型的模型并行性互补并兼容,对于不适合单个节点的大型模型,它能够显着提升性能,节省资源等等优点。
三、Reddit 评价:褒贬不一
正如文章开头所称,微软DeepSpeed中利用ZeRO-OS来训练一个170亿参数的Turing-NLG模型,训练结果表明其准确性和训练效率高于当前的最新方法。
与单独使用NVIDIA Megatron-LM相比,ZeRO-OS能够大量节省内存,并使Turning-NLG模型的模型并行度降低到原来1/4,批处理量增大4倍,吞吐量增长3倍。
至于这自带170亿参数的Turing-NLG模型,也在社交媒体上引起了不少讨论,Reddit的“r/MachineLearning”版面中,仅仅10个小时,相关话题热度已经达到了216,70多人发表了看法。
跟帖最高的一条评论是这样说的:幸好是170亿个参数,而不是170亿个超参数。当前最智能的机器有着超过100万亿的参数(他这里说的是人类),并不否认效率也很重要,但是在资金充足的情况下,参数多一些并没有什么错呀。
针对这条评论,也有人回应说,这种比较没有意义,想想神经元之间的质量差异,尤其是最新研究单表明,单个人类神经元也可以异或运算,这就相当于2层人工神经网络了。
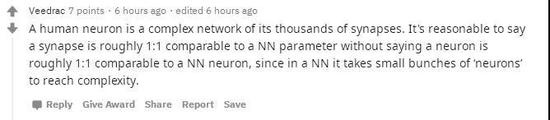
也有评论将讨论引入了复杂的生物学:人类神经元是其数千个突触的复杂网络。合理地说,突触与NN参数可比约为1:1,而神经元与NN神经元可比约为1:1,因为在NN中,需要一小束“神经元”才能达到复杂性。
吃瓜群众质疑道:提起图灵,我就想起了“营销”,
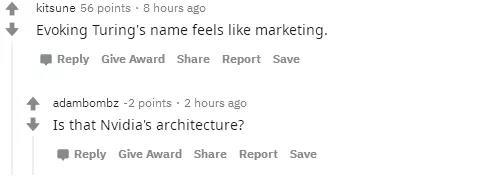
吃瓜群众质疑道:提起图灵,我就想起了“营销”,
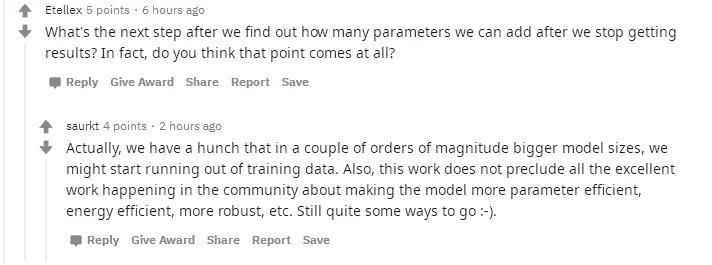
当然,也有更加专业的讨论:知道添加多少个参数之后,下一步怎么办?

这条消息的发布者指出了这项工作的不足:是否有足够的VRAM在单个GPU上运行模型仍然没有解决。

也有网友提到了碳排放:更多的参数意味着更多的碳消耗。那么,你对此模型有何看法?











































